An evolving hardware landscape Link to heading
In September 2023, Wes McKinney, creator of the Pandas library, published an illuminating blog post describing his thoughts on 15 years of evolution in data management systems. In particular, he highlights the impact of modern hardware in pushing the industry towards a more modular, composable data stack. It’s no wonder, then, that his friend, colleague and co-author of Pandas, Chang She happens to be the founder of LanceDB, a developer-friendly embedded vector database that aligns very well with this vision, and is the focus of the third post in this series.
LanceDB is an open source, embedded and developer-friendly vector database. Some of its key features (among many others) that make it different from a number of existing solutions are listed below:
- Incredibly lightweight (no DB servers to manage), because it is entirely in-process
- Extremely scalable from development to production
- Ability to perform full-text search (FTS), SQL search and vector search
- Multi-modal data support (images, text, video, audio, point-clouds, etc.)
- Zero-copy (via Arrow) with automatic versioning of data
The aim of this post is to understand the internals of LanceDB, and to showcase its performance on full-text and vector search via serial and concurrent workflows.
Towards “deconstructed databases” Link to heading
The term deconstructed database1 was coined in 2019 by Julien Le Dem, one of the original designers of the Parquet file format and Arrow specification. These database systems deviate from the well-known vertically-integrated systems that have dominated the DB landscape for decades. Instead, they are built from a collection of modular, reusable components, each of which can be developed and optimized by entirely separate groups of people, typically as open source projects.
In his blog2, Wes points out that today’s compute hardware is radically different from what it was in 2013, when Parquet was conceived. In particular, the availability of blazing fast SSDs and NVMe drives have led to a shift in thinking toward designing systems that can store and query specialized data types like vectors and time series at scale. This explains the development of Lance, a new data format for the age of AI.
The composition of LanceDB Link to heading
With these ideas in mind, let’s deconstruct LanceDB. On the surface, it is a vector database written in Rust, but underneath, it’s a collection of specialized modular components which are themselves independent components of the Rust 🦀 tooling ecosystem.
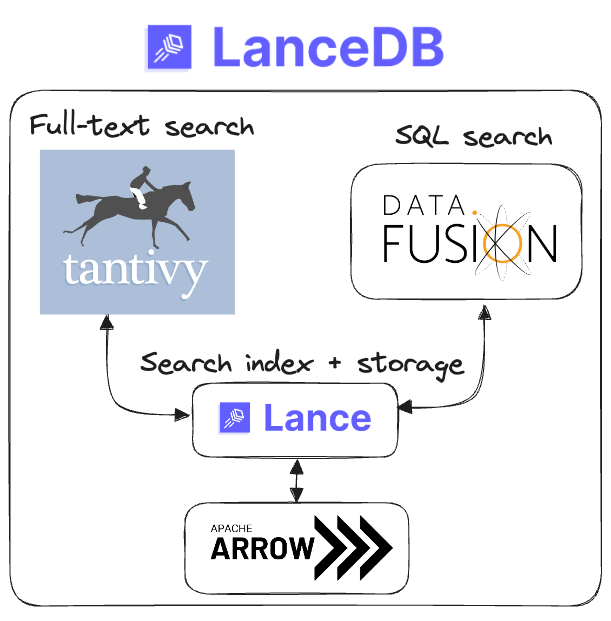
The modular components of LanceDB
LanceDB implements its own vector indexes on top of the underlying Lance data format, using either an IVF-PQ or an upcoming DiskANN index. Tantivy is an open source full-text search engine incorporated to allow keyword-based search via BM25. DataFusion, an embeddable SQL query engine, is used to power the full-text/vector search queries via a SQL interface. The Apache arrow format is used to allow a smooth transition between in-memory and on-disk data storage, and also for seamless interoperability with other data formats from systems like DuckDB, Pandas or Polars.
Lance Link to heading
Lance is the persistent storage format used in LanceDB. It is optimized for machine learning datasets and workflows, and can be thought of as an alternative to Parquet that’s highly optimized for ultra fast scans and random access on vectors. In addition, it has great support for multi-modal data (images, text, video, audio, point-clouds, etc.) in a zero-copy manner, thanks to its integration with the Arrow ecosystem.
Arrow Link to heading
It’s impossible to overstate the impact that Apache Arrow2 has had on the consolidation of analytical tooling in the industry, due to the way it connects disparate portions of the data stack via an in-memory, language-agnostic specification. The following key features of Arrow2 are relevant:
- Column-oriented in-memory operation optimized for fast analytical processing
- Zero-copy, chunk-oriented data layer designed for moving and accessing large amounts of data from disparate storage layers
- Extensible type metadata for describing a wide variety of flat and nested data types occurring in real-world systems, with support for user-defined types
Lance is based on the Rust implementation of Arrow, arrow-rs, and was itself rewritten from the ground up in Rust in 20233 (having originally been written in C++).
DataFusion Link to heading
DataFusion is a fast, extensible, embeddable query engine that supports a SQL API, and can be used to query data stored in Arrow and Lance. In recent times, it has become the standard for building domain-specific query engines that are decoupled from the storage layer, and because it’s written in Rust, performance is excellent despite not being natively integrated with the storage layer. Due to its extensibility, DataFusion has been re-purposed to generate optimized query plans for LanceDB for full-text/vector search via a unified SQL interface.
Tantivy Link to heading
Tantivy is a full-text search engine library written in Rust. It’s very similar to Apache Lucene (which is written in Java), but Tantivy is faster4 and more memory efficient. Just like Lucene, Tantivy is not intended to be user-facing, but rather, is used as the basis of a downstream system such as LanceDB. Tantivy uses the BM25 algorithm for scoring documents, and supports boolean queries, phrase queries, fuzzy queries, and range queries. Incorporating Tantivy into LanceDB allows for full-text search queries that run directly on a Lance dataset.
Embedded vs. serverless Link to heading
It is common to see the terms “embedded” and “serverless” used interchangeably, but for a database, they are not the same architecturally. LanceDB is available to users in two flavours:
- Open source LanceDB is embedded, meaning that the storage layer and the application layer are tightly coupled, and are typically on the same instance/machine
- LanceDB Cloud (a commercial product) is serverless, meaning that storage and compute are clearly separated. This is done by connecting the application client to a remote database via a network connection, with the application layer and storage layer being scaled independently of one another.
Benchmark: Full-text and vector search Link to heading
Studying the performance of any tool in isolation doesn’t make much sense, so for the sake of comparison, an Elasticsearch workflow is provided in this repo. Elasticsearch is a popular full-text and vector search engine based on Lucene (which Tantivy is inspired by), so this makes it a meaningful comparison for a benchmark.
🚩 This is a preliminary analysis designed to test the quality and throughput of FTS and vector search, so the results of the benchmarks are inspected on both these counts. It is expected that the numbers shown below for LanceDB will continually improve as new versions are released, and as each underlying system improves.
As always, any benchmark should be performed on your own data and hardware to get a sense for your use case.
Dataset Link to heading
The dataset used is the same one I’ve used in prior blogs, i.e., a wine reviews dataset from Kaggle. It consists of 129,971 wine reviews from the Wine Enthusiast magazine, made available in newline-delimited JSON as shown below. Refer to the Kaggle source for more detailed information on the dataset and how it was scraped.
An example JSON line containing a wine review and its metadata is shown below.
{
"id": 40825,
"points": "90",
"title": "Castello San Donato in Perano 2009 Riserva (Chianti Classico)",
"description": "Made from a blend of 85% Sangiovese and 15% Merlot, this ripe wine delivers soft plum, black currants, clove and cracked pepper sensations accented with coffee and espresso notes. A backbone of firm tannins give structure. Drink now through 2019.",
"taster_name": "Kerin O'Keefe",
"taster_twitter_handle": "@kerinokeefe",
"price": "30.0",
"designation": "Riserva",
"variety": "Red Blend",
"region_1": "null",
"region_2": null,
"province": "Tuscany",
"country": "Italy",
"winery": "Castello San Donato in Perano"
}
Full-text search (FTS) queries Link to heading
Tantivy supports the same syntax as the Lucene query parser, in which the + symbol represents the AND boolean operator. The following ten keyword-based queries are used to search the description field of the dataset. For example, the first query below searches for documents that contain both the words apple and pear in the description field.
+apple +pear
"tropical fruit"
+citrus +almond
+orange +grapefruit
+full +bodied
"citrus acidity"
+blueberry +mint
+beef +lamb
+shellfish +seafood
+vegetable +fish
Vector search queries Link to heading
Ten vector search queries are defined as shown below. The first query below searches for documents whose description fields are similar to the vector representation of the words vanilla and smoky. The second query searches for descriptions similar to dessert, sweetness and tartness in vector space. You get the idea!
vanilla and a hint of smokiness
rich and sweet dessert wine with balanced tartness
cherry and plum aromas
right balance of citrus acidity
grassy aroma with apple and tropical fruit
bitter with a dry aftertaste
sweet with a hint of chocolate and berry flavor
acidic on the palate with oak aromas
balanced tannins and dry and fruity composition
peppery undertones that pairs with steak or barbecued meat
Serial benchmark Link to heading
The serial benchmark involves sequentially running up to 10,000 randomly sampled queries in a Python for loop. This isn’t representative of a realistic use case in production, but is useful to understand the throughput potential of the underlying search engines for either system.
We first randomly sample the FTS and vector search queries, with repetition, to generate a list of queries to run sequentially.
import random
# Generate a list of 10,000 randomly sampled queries from the existing list of queries
random_choice_queries = [random.choice(queries) for _ in range(10_000)]
These are run in a for loop for the serial benchmark:
# args.search is either "fts" or "vector"
# Searches a LanceDB Table
for query in random_choice_queries:
if args.search == "fts":
fts_search(tbl, query)
else:
# MODEL is an embedding model that converts the text query to a vector
vector_search(MODEL, tbl, query)
The script benchmark_serial.py is run with the following command line arguments:
python benchmark_serial.py --search fts --limit 10
python benchmark_serial.py --search fts --limit 100
python benchmark_serial.py --search fts --limit 1000
python benchmark_serial.py --search fts --limit 10000
Concurrent benchmark Link to heading
Concurrent requests are a much more realistic use case, for example, when a user interface sends multiple queries to the database at the same time. The concurrency approach (for now) is different between LanceDB and Elasticsearch, due to the fact that LanceDB (for now) exposes a synchronous client connection, whereas Elasticsearch implements an asynchronous, non-blocking client connection.
Concurrent FTS and vector searches on Elasticsearch are performed by using its official async Python client, as per app.py in the repo.
The concurrent.futures.ThreadPoolExecutor class is used in Python, allowing the user to run multi-threaded queries via a custom FastAPI endpoint. See the code for the FastAPI app that’s built on top of LanceDB here.
The FTS search takes in a FastAPI Request object and the search query, and returns a list of SearchResult objects, which are Pydantic models that contain specific fields that are validated prior to returning the response.
def _fts_search(request: Request, terms: str) -> list[SearchResult] | None:
# In FTS, we limit to a max of 10K points to be more in line with Elasticsearch
search_result = (
request.app.table.search(terms, vector_column_name="description")
.select(["id", "title", "description", "country", "variety", "price", "points"])
.limit(10)
).to_pydantic(SearchResult)
if not search_result:
return None
return search_result
The vector search is performed the same way, except that we first convert the query to a vector representation using the embedding model. The query then specifies the number of probes to divide the search space into, for the IVF-PQ index. Just like in the FTS case, the result is converted to a Pydantic model and returned as JSON via the REST endpoint.
def _vector_search(
request: Request,
terms: str,
) -> list[SearchResult] | None:
query_vector = request.app.model.encode(terms.lower())
search_result = (
request.app.table.search(query_vector)
.metric("cosine")
.nprobes(20)
.select(["id", "title", "description", "country", "variety", "price", "points"])
.limit(10)
).to_pydantic(SearchResult)
if not search_result:
return None
return search_result
The script benchmark_concurrent.py is run with the following command line arguments:
python benchmark_concurrent.py --search fts --limit 10
python benchmark_concurrent.py --search fts --limit 100
python benchmark_concurrent.py --search fts --limit 1000
python benchmark_concurrent.py --search fts --limit 10000
Results Link to heading
- The timing numbers below are from a 2022 M2 Macbook Pro with 16GB RAM
- The dimensionality of the embeddings is 384 (
BAAI/bge-small-en-v1.5) - The distance metric for vector search is cosine similarity in either DB
- Vector search in Elasticsearch is based on HNSW, and in LanceDB, is based on IVF-PQ
Qualitative inspection Link to heading
The first thing to check is whether each set of queries return sensible results. The results are inspected qualitatively, by checking that the top result (based on either FTS or vector similarity score) is similar to the query. This is done for both LanceDB and Elasticsearch via the script query.py. Switch between the tabs below to see the results for either solution.
Query [+apple +pear]: The pear, apple and apple skin aromas are light. The palate brings just off-dry pear flavors with a full feel.
Query ["tropical fruit"]: Plump tropical fruit aromas show on the nose. A fruity but not complex palate deals short melon and tropical-fruit flavors prior to a briny finish.
Query [+citrus +almond]: Inviting aromas of butter, almond and citrus open into a rich, thickly textured wine studded with peach, almond butter and citrus pith. The slightly bitter notes echo through the finish, providing a welcome sense of balance to round mouthfeel and fatty flavors.
Query [+orange +grapefruit]: Made from Cabernet Sauvignon, this has funky, yeasty aromas of pink grapefruit and passion fruit that turn citrusy and briny if given time. On the palate, this recalls orange juice. Orange, grapefruit and generic tang proceed from the flavor profile to the finish.
Query [+full +bodied]: Produced from organically grown grapes, this wine is full of fragrant, clean red-fruit flavors. It is ripe and full bodied—perhaps too full-bodied for a really fresh rosé. It does have all the fruit, generous and with a soft aftertaste.
Query ["citrus acidity"]: This soft, ripe wine has good apricot and peach flavors alongside the crisper citrus acidity. It is spicy, fruity and ready to drink.
Query [+blueberry +mint]: Exotic aromas of cardamom, blueberry and spiced currant filter onto a fresh but wide-bodied palate with raspberry, blueberry, herb and spice flavors. The finish is intriguing due to a reprise of notes like anise, mint and herbal berry flavors.
Query [+beef +lamb]: Tarry, savory notes of dried beef, soy, charred lamb and underlying blackberry combine for a nose that screams umami. The palate carries a similar effect of grilled, lavender-covered lamb shank, black peppercorns and black sesame.
Query [+shellfish +seafood]: Really? A five-buck Oregon Riesling? It's light, lemony and tart, but it's real wine, simple and plain, yet fine with shellfish or other light seafood.
Query [+vegetable +fish]: Clean mineral notes blend nicely with fresh berry fruit, red rose and raspberry. This is a simple but genuine wine that would pair with roasted fish or vegetable risotto.
Query [+apple +pear]: The pear, apple and apple skin aromas are light. The palate brings just off-dry pear flavors with a full feel.
Query ["tropical fruit"]: Plump tropical fruit aromas show on the nose. A fruity but not complex palate deals short melon and tropical-fruit flavors prior to a briny finish.
Query [+citrus +almond]: Inviting aromas of butter, almond and citrus open into a rich, thickly textured wine studded with peach, almond butter and citrus pith. The slightly bitter notes echo through the finish, providing a welcome sense of balance to round mouthfeel and fatty flavors.
Query [+orange +grapefruit]: Made from Cabernet Sauvignon, this has funky, yeasty aromas of pink grapefruit and passion fruit that turn citrusy and briny if given time. On the palate, this recalls orange juice. Orange, grapefruit and generic tang proceed from the flavor profile to the finish.
Query [+full +bodied]: Produced from organically grown grapes, this wine is full of fragrant, clean red-fruit flavors. It is ripe and full bodied—perhaps too full-bodied for a really fresh rosé. It does have all the fruit, generous and with a soft aftertaste.
Query ["citrus acidity"]: This soft, ripe wine has good apricot and peach flavors alongside the crisper citrus acidity. It is spicy, fruity and ready to drink.
Query [+blueberry +mint]: Exotic aromas of cardamom, blueberry and spiced currant filter onto a fresh but wide-bodied palate with raspberry, blueberry, herb and spice flavors. The finish is intriguing due to a reprise of notes like anise, mint and herbal berry flavors.
Query [+beef +lamb]: Tarry, savory notes of dried beef, soy, charred lamb and underlying blackberry combine for a nose that screams umami. The palate carries a similar effect of grilled, lavender-covered lamb shank, black peppercorns and black sesame.
Query [+shellfish +seafood]: Really? A five-buck Oregon Riesling? It's light, lemony and tart, but it's real wine, simple and plain, yet fine with shellfish or other light seafood.
Query [+vegetable +fish]: Clean mineral notes blend nicely with fresh berry fruit, red rose and raspberry. This is a simple but genuine wine that would pair with roasted fish or vegetable risotto.
As can be seen, the FTS results for LanceDB and Elasticsearch are identical to one another, which is heartening, considering that we had to do zero work to set up the search index via Tantivy. In Elasticsearch, we had to define the index settings via mappings.json, which adds a bit of a learning curve and boilerplate.
The vector search results are also inspected the same way. Switch between the tabs below to see the results for either solution.
Query [vanilla and a hint of smokiness]: Drenched in luxurious, almost sweet fruit flavors, this tempting and delicious wine is full bodied. Ripe in aromas and on the palate, it creates a vivid and warming cherry-pie effect on the senses, and is undeniably tasty.
Query [rich and sweet dessert wine with balanced tartness]: Not a lot of wood scents are showing, though the aging took place in roughly 50% new oak barrels. This has forward, pretty black fruits, juicy acids, some still-unresolved astringency, and aromatically it incorporates a nice herbal note, reminiscent of green tea. Still too young to drink, and the rating could go higher with more bottle age.
Query [cherry and plum aromas]: Part of the select group of impressive wines from this year, this wine is ripe, rich and firmly structured. Black-currant fruitiness forms the base for solid tannins and a concentrated texture. The hints of wood-aging need to soften. Drink from 2022.
Query [right balance of citrus acidity]: This straightforward wine isn't particularly Cabernet-like, but it is good and sound. With furry tannins, it has a distinct sweetness of raisins and blackberry jam, as well as lots of brambly Zinny spices. Drink up.
Query [grassy aroma with apple and tropical fruit]: This is the finest Cheval Blanc for many years. It is, quite simply, magnificent. The wine shows the greatness of Cabernet Franc in the vintage, with 57% of the variety in the blend. It is beautifully structured and perfumed, with velvety tannins, balanced acidity and swathes of black-currant and black-cherry fruits. It's well on course to becoming a legendary wine.
Query [bitter with a dry aftertaste]: The wine is firm with tannins as well as black-currant fruit. It does have a juicy edge that will develop well as it matures. Drink this potentially attractive wine from 2018.
Query [sweet with a hint of chocolate and berry flavor]: Exotic, complex and vivid aromas, rich and fulfilling fruit flavors and a hefty structure form a great package in this full-bodied and extroverted wine. The winemaker allowed wild yeast and kept 30% whole clusters in the fermentation, then aged it in neutral barrels.
Query [acidic on the palate with oak aromas]: A lovely young Cab, rich and balanced, and with the elegance you expect from this producer. Made from all 5 Bordeaux varieties, with a drop of Syrah, the wine is potent in red and black currant, blackberry and new oak flavors, with sweetly ripe tannins. Delicious now, it should develop through 2015.
Query [balanced tannins and dry and fruity composition]: A 100% varietal Pinot, this wine has a faint bouquet of ripe black cherry and blackberry, exuding full flavor and body. Smooth, the oak is low impact, providing extra weight and sustenance while remaining balanced with the fruit.
Query [peppery undertones that pairs with steak or barbecued meat]: This arresting wine has aromas of forest floor, strawberry and cola. It's light and lithe in feel yet still richly flavored with a lingering finish.
Query [vanilla and a hint of smokiness]: Vanilla and maple aromas lead to overtly fruity red cherry flavors with a touch of sweetness and a soft texture. It's pleasant to drink for those looking for a soft touch, with very mild acidity and no tannin to speak of.
Query [rich and sweet dessert wine with balanced tartness]: This richly extracted dessert wine boasts a dark, inky appearance and aromas of exotic spice, nutmeg, cinnamon, dark chocolate, carob, roasted chestnut and mature blackberries. It is smooth, well textured and exceedingly rich on the close with loads of power, personality and persistency.
Query [cherry and plum aromas]: Earthy, herbal aromas of cherry and plum come with a funky note of wet dog fur. Hailing from a cool, wet vintage, this is showing shearing acidity and abrasiveness. Quick-hitting raspberry, plum and red-currant flavors end with edginess and snap. This is 40% each Cabernets Sauvignon and Franc, with 20% Monastrell.
Query [right balance of citrus acidity]: True to its name, this blend is tangy in acidity. Flavorwise, it's simple, with pleasant orange, peach, lemon and vanilla flavors that finish a little sweet.
Query [grassy aroma with apple and tropical fruit]: Spring flower aromas mingle with a hint of orchard fruit. On the lean, extremely simple palate, yellow apple fruit mixes with a lemon zest note.
Query [bitter with a dry aftertaste]: Even at a considerable 15 g/l of residual sugar, this wine comes across as almost dry, thanks to its crisp acidity. Scents of petrichor, green apple and lime start things off, while those razor-sharp acids show up on the finish. Drink now.
Query [sweet with a hint of chocolate and berry flavor]: A bouquet of cherry, white chocolate and juniper berry sets the stage for flavors of raspberry, blackberry, blueberry pie and baking spices. It is smooth in the mouth, with a sense of soft sweetness that is neither overpowering nor cloying, bolstered by a pervasive backbone of acidity.
Query [acidic on the palate with oak aromas]: The oaky smoke is quite powerful on the nose, which also shows vanilla dust and lime juice. The palate is anything but austere, full of toast, caramelized apples and smoked fruits. A line of citrus acidity stops it from becoming flabby, but this is definitely for the oak lovers crowd.
Query [balanced tannins and dry and fruity composition]: There is a good core of tannin here, the fruit sweet plums and ripe tannins, relatively soft and easy. Only that kernel of tannin offers some aging possibility.
Query [peppery undertones that pairs with steak or barbecued meat]: An easy red blend, this would pair well with hamburgers or grilled meats. Notes of cherry and blackberry accent the palate.
Due to differences in the underlying vector index: IVF-PQ for LanceDB and HNSW for Elasticsearch, we would expect minor differences in the vector search results, as can be seen above. However, the results make qualitative sense and either solution can be further tuned (to improve recall) by adjusting the hyperparameters of the underlying vector index.
Throughput Link to heading
Because the Lance format is optimized for disk-based I/O and random access, LanceDB is capable of handling a much higher throughput than Elasticsearch for vector search. The results of the serial and concurrent benchmarks are shown below.
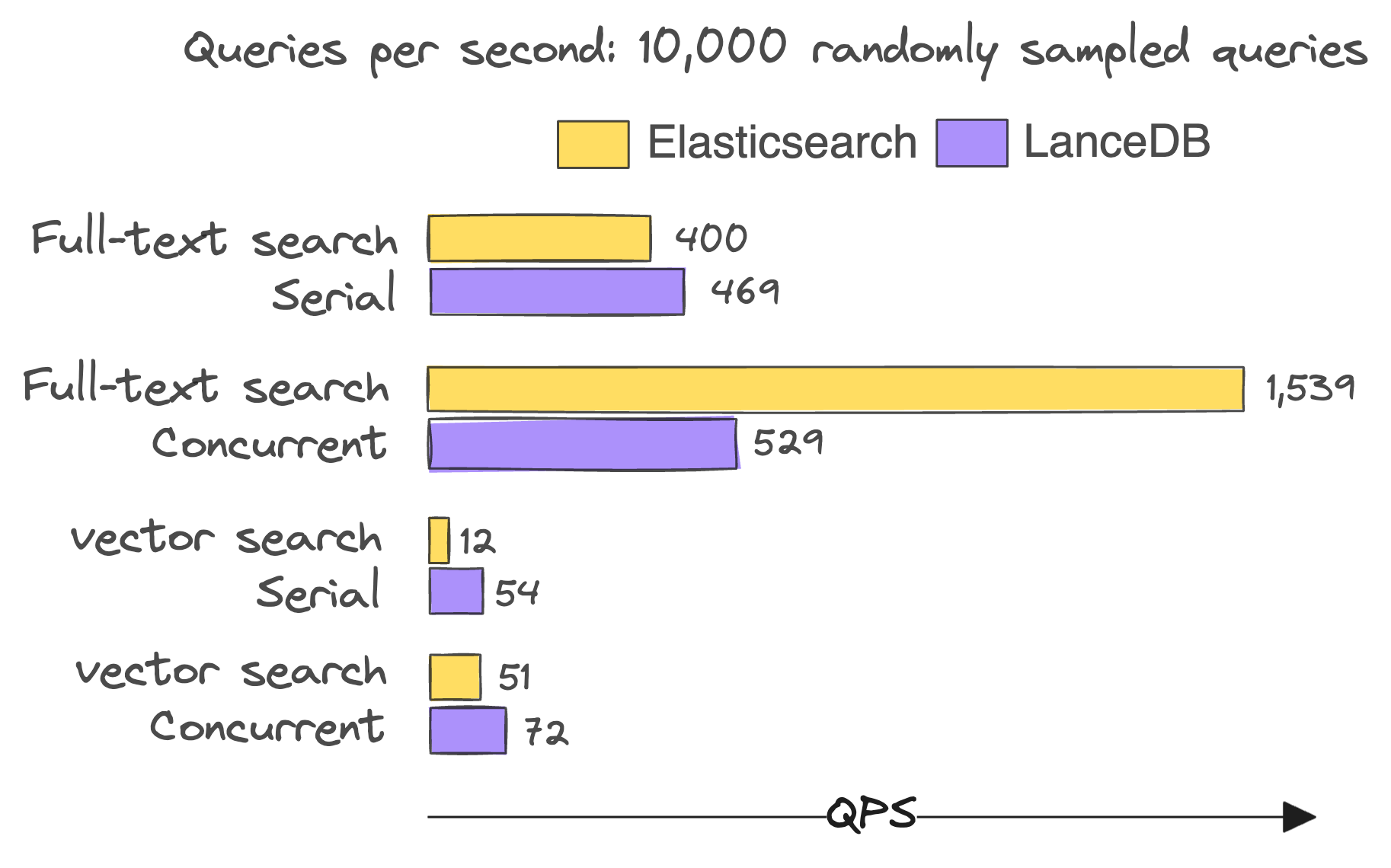
QPS for 10,000 randomly sampled FTS and vector search queries
The speedup factor over a single-node Elasticsearch deployment when using LanceDB is shown below.
- FTS (serial): 1.2x
- FTS (concurrent): 0.3x
- Vector search (serial): 4.5x
- Vector search (concurrent): 1.4x
For vector search, it is clear LanceDB is faster than Elasticsearch in both serial and concurrent scenarios. Elasticsearch uses Lucene’s HNSW implementation, which has known performance issues5. Additionally, the client/server nature of Elasticsearch can involve an incremental serialization/deserialization overhead as data passes through the network. It is, of course, possible to improve the throughput of Elasticsearch with more compute resources, a larger cluster, and careful tuning of its HNSW index settings, but that’s just as true for the IVF-PQ settings in LanceDB. The difference is that LanceDB is likely to perform on par with or better than Elasticsearch, with far fewer resources on a single node.
The surprising result in FTS is that LanceDB is only about 30% as fast as Elasticsearch in the concurrent FTS case, while being 1.2x faster in the serial case. The performance drop of LanceDB in the concurrent FTS case is likely due to the overhead of multi-threaded REST API calls, and not due to the underlying search engine, Tantivy. Elasticsearch implements a non-blocking async client, which is likely the reason for its superior performance in the concurrent FTS case.
A deeper explanation for the less-than-desired multi-threaded performance of LanceDB/FastAPI is that the current version of LanceDB sits on top of Tantivy’s Python client API, tantivy-py, and through this layer, there could be blocking operations occurring that are holding the GIL. This could potentially be addressed in a future version of Lance by directly connecting it to Tantivy’s Rust API and performing FTS queries with true multi-threading at the Rust level.
As mentioned before, increasing the number of concurrent worker threads in the FastAPI application is detrimental to performance, likely because the CPU-bound embedding generation and IO-bound query operations were competing for resources. This is something that can potentially be improved in the future by using an async LanceDB client that’s more efficient at context-switching in such hybrid CPU-bound + IO-bound scenarios.
Composable systems improve nonlinearly Link to heading
A key takeaway from this study (other than the obvious performance gains possible), is how composing multiple modular components leads to a nonlinear improvement in the performance of the overall system. That is, improvements at the lower levels of the stack can result in an rapid, outsized improvement in the upper level at which the database sits.
As can be seen below, LanceDB is composed of the following key components of the Rust ecosystem (not counting foundation crates like serde for serialization/deserialization or tokio for async). The effects of each of these projects propagate up the stack to the Lance storage layer, and ultimately, the database itself.
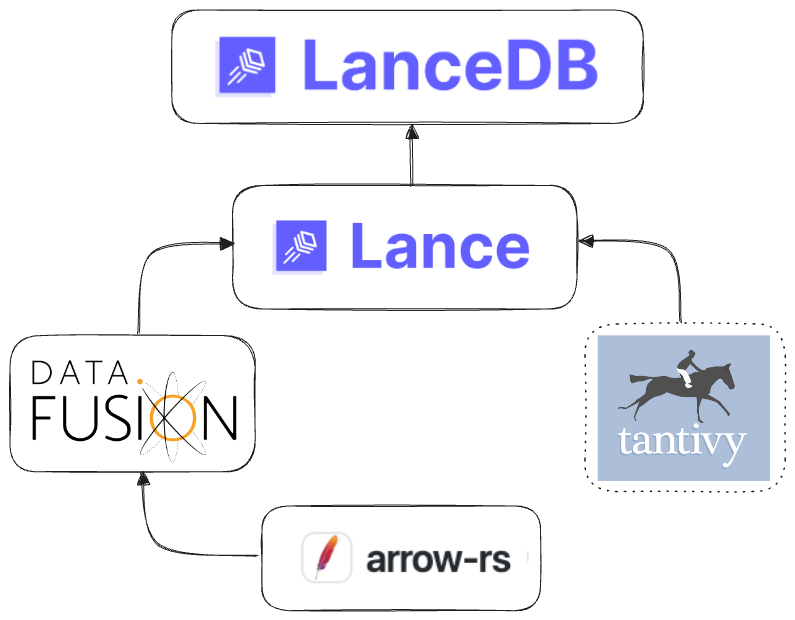
Composing multiple powerful Rust-based systems in LanceDB
Because arrow-rs is a key foundational project that develops rapidly on its own via the thriving open source ecosystem it’s part of, it ultimately impacts other key projects downstream like Parquet, DataFusion and Lance. Tantivy, which is an independent open source project that specializes in its domain, will also improve with time as its use becomes more widespread in other search tools. The developers of LanceDB can thus focus on building out their core functionality, which is to provide a powerful vector DB with modern vector indexes and data versioning with scalability and performance in mind, while also leveraging the larger developments in the Arrow-enabled analytical tooling ecosystem.
Future developments in the Lance ecosystem Link to heading
As described in this post, LanceDB is an exciting addition to the vector database landscape because of its refreshingly different internals, and its interesting approach to composability. As of writing this post, there are already numerous developments ongoing in both open source (OSS) LanceDB, as well as its commercial product, LanceDB Cloud. Its adoption will no doubt increase over time as more and more developers discover the ease of use and its lightweight nature. Of all the features on its roadmap, I’m particularly looking forward to the following:
- Async support for all its client APIs
- Support for disk-based vector indexes (e.g., DiskANN)
- Hybrid search features that combine the benefits of keyword-based and semantic search
- Faster vectorization and data loading via async/multi-processing task pipelines
- Support for upserts and easy updates/deletes for vectors whose representations change over time
- Direct full-text search on object storage (e.g., S3) via Tantivy
I highly recommend giving out LanceDB a try on your own data, and to keep an eye on its development in the coming months. Give both Lance and LanceDB a ⭐️ on GitHub and show them some ❤️ on Discord.
Code Link to heading
All the code required to reproduce the results from the benchmark is available here.
How Apache Arrow Is Changing the Big Data Ecosystem, thenewstack.io ↩︎
The Road to Composable Data Systems: Thoughts on the Last 15 Years and the Future, wesmckinney.com ↩︎ ↩︎ ↩︎
Please pardon our appearance during renovations, by Chang She, LanceDB blog ↩︎
Search benchmark, the game, Tantivy blog ↩︎
Make HNSW merges faster, Lucene GitHub ↩︎